Какво представляват клъстерите?
Услугата клъстери е система от взаимосвързани компютри или сървъри, които работят синхронно, като единна изчислителна единица, за да изпълняват задачи с висока ефективност и надеждност. MD Zero разработва тези системи с фокус върху подобряване на производителността, сигурността и устойчивостта на ИТ инфраструктурата на бизнеса. От техническа гледна точка, клъстерите са базирани на концепцията за разпределено изчисление (distributed computing), при което работното натоварване се разпределя между множество възли (nodes), свързани чрез високоскоростна мрежа като InfiniBand, 10Gb Ethernet или дори 100Gb Ethernet в по-сложни конфигурации. Този подход позволява обработка на огромни обеми данни, изпълнение на сложни изчислителни задачи и осигуряване на непрекъснатост на услугите дори при срив на отделни компоненти.
Основни компоненти на клъстера
Всеки клъстер, се състои от няколко ключови елемента: главен възел (master node), работни възли (worker nodes), мрежова инфраструктура и софтуер за управление. Главният възел играе ролята на координатор, който разпределя задачите и следи състоянието на системата чрез протоколи като heartbeat или quorum-based консенсус. Работните възли, от своя страна, изпълняват конкретните операции – от обработка на уеб заявки до изчисления с висока интензивност. Мрежовата инфраструктура обикновено включва комутатори (switches) с поддръжка на VLAN и QoS (Quality of Service), за да се гарантира ниска латентност и висока пропускателна способност. Софтуерът за управление, като Kubernetes, Apache Mesos или собствените решения на MD Zero, осигурява оркестрация, балансиране на натоварването и автоматично мащабиране.
Технически принципи на работа
На ниво операционна система клъстерите често използват Linux дистрибуции като CentOS, Ubuntu Server или Red Hat Enterprise Linux (RHEL), които поддържат разпределени файлови системи като GlusterFS, Ceph или Hadoop Distributed File System (HDFS). Тези системи позволяват на всички възли да имат достъп до споделени данни в реално време, което е критично за приложения, като бази данни (напр. MySQL Cluster, PostgreSQL с репликация) или аналитични платформи (напр. Apache Spark). MD Zero интегрира тези технологии, за да осигури безпроблемна работа и висока производителност, като същевременно адаптира конфигурацията към специфичните нужди на клиента – например, използване на NVMe SSD дискове за по-бърз достъп до данни или GPU ускорение за задачи, свързани с машинно обучение.
Защо MD Zero е лидер в тази област?
Фирмата MD Zero се отличава с дългогодишен опит в проектирането и управлението на клъстери, предлагайки решения, които са както технически напреднали, така и икономически изгодни. Компанията е специализирана в сложни архитектури, включително хибридни клъстери, които комбинират локални сървъри с облачни платформи като Amazon Web Services (AWS), Microsoft Azure или Google Cloud Platform (GCP). Този подход позволява на бизнеса да се възползва от гъвкавостта на облака, като същевременно запазва контрола върху критичните си данни на локално ниво.
Защо са важни за бизнеса?

Непрекъснатост на операциите
В съвременния бизнес всяко прекъсване на услугите може да доведе до значителни финансови загуби и репутационни щети. Клъстерите, осигуряват висока наличност (High Availability, HA) чрез резервираност на системите. Например, в HA конфигурация, ако един сървър в клъстера се повреди, задачите му се прехвърлят автоматично към друг възел чрез механизми като heartbeat мониторинг (за откриване на сривове) и автоматично превключване (failover). Това е особено важно за критични приложения като онлайн магазини, финансови платформи или системи за управление на веригата на доставки, където дори няколко минути престой могат да струват милиони.
Конкурентно предимство чрез технологии
С бързото развитие на пазара компаниите трябва да реагират незабавно на промените в търсенето и потребителското поведение. MD Zero внедрява клъстери, които позволяват автоматизация на процесите – от управление на уеб трафик с балансьори като HAProxy до обработка на големи обеми клиентски заявки чрез разпределени опашки (напр. RabbitMQ или Kafka). Това дава на бизнеса предимство чрез по-бързо време за реакция, по-добра адаптивност и възможност за мащабиране в реално време, когато трафикът или натоварването се увеличат.
Финансови ползи и дългосрочна устойчивост
Инвестицията в клъстери намалява дългосрочните разходи за ИТ инфраструктура, тъй като системата е по-ефективна в сравнение с традиционните единични сървъри. MD Zero оптимизира тези решения, за да намали консумацията на енергия чрез използване на енергийно ефективни компоненти (напр. захранвания с 80 PLUS Titanium сертификат) и да минимизира разходите за поддръжка чрез автоматизирани процеси за диагностика и ремонт. Освен това, клъстерите позволяват по-добро използване на съществуващия хардуер, което удължава живота на инвестициите в ИТ.
Основни предимства
Скалируемост и гъвкавост
Едно от най-големите предимства на клъстерите е тяхната скалируемост. Системата може да се разширява хоризонтално чрез добавяне на нови възли, без да се налага прекъсване на текущите операции или пълно преконфигуриране на инфраструктурата. Например, при увеличаване на уеб трафика, MD Zero може да интегрира допълнителни сървъри в рамките на минути, като използва инструменти за балансиране на натоварването като HAProxy, Nginx или дори облачни решения като AWS Elastic Load Balancer (ELB). Това е особено полезно за сезонни бизнеси или компании с променливи натоварвания.
Висока производителност и надеждност
Клъстерите използват паралелна обработка, което значително увеличава скоростта на изпълнение на задачи. Надеждността се постига чрез резервираност – ако един възел спре да работи, друг поема неговите задачи без забавяне, благодарение на системи като Pacemaker или Keepalived.
Намаляване на разходите
В сравнение с традиционните сървъри, клъстерите предлагат по-добра ефективност при по-ниски оперативни разходи. MD Zero използва виртуализация чрез платформи като VMware vSphere, KVM или Hyper-V, за да увеличи максимално използването на хардуера.
Как работят клъстерите?
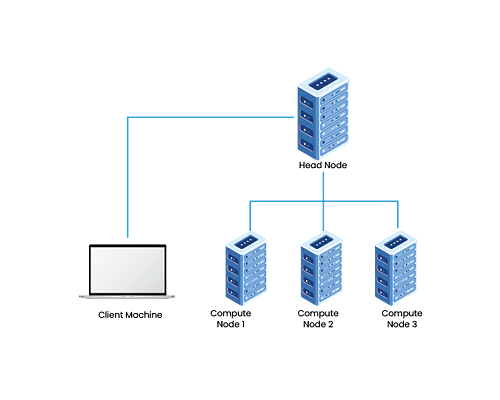
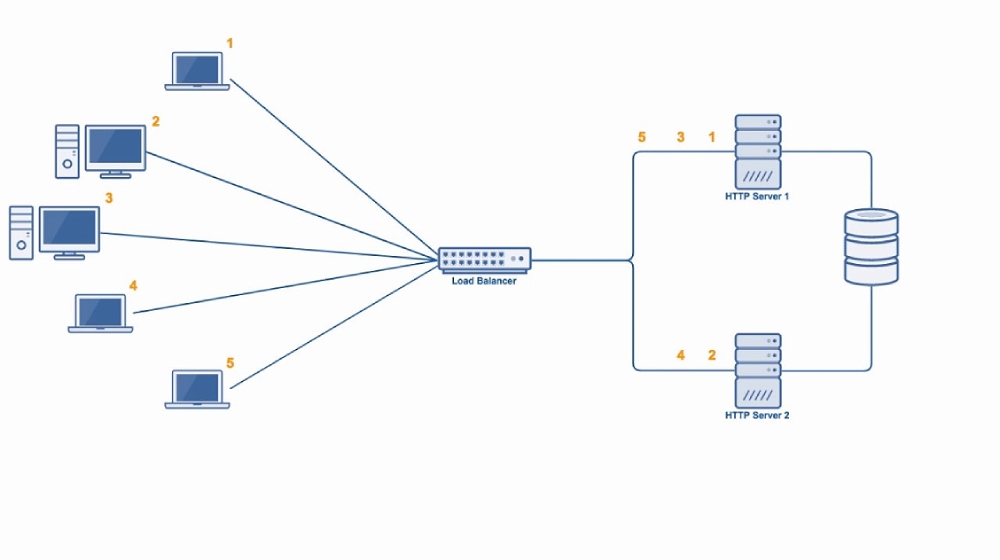
Принцип на действие
Клъстерите функционират чрез разпределяне на задачите между множество възли, свързани чрез мрежа с ниска латентност и висока пропускателна способност. MD Zero използва софтуер за оркестрация като Kubernetes, който автоматично разпределя работните натоварвания между възлите и управлява контейнери чрез Docker или Podman. Например, при обработка на уеб заявки, главният възел анализира текущото натоварване и изпраща задачите към най-малко натоварения работен възел, като използва алгоритми за кръгово разпределение (round-robin) или на базата на тежест (weighted distribution).
Техническа архитектура
Архитектурата на един клъстер включва няколко нива. На хардуерно ниво имаме сървъри с многоядрени процесори (напр. Intel Xeon Scalable или AMD EPYC), бърза памет (DDR4/DDR5 ECC RAM) и високоскоростни дискове (NVMe SSD или SAS HDD в RAID конфигурации). Мрежата е изградена с протоколи като TCP/IP за стандартна комуникация или RDMA (Remote Direct Memory Access) за приложения с високи изисквания към скоростта, като HPC задачи. Разпределените файлови системи, като GlusterFS или Ceph, осигуряват споделен достъп до данни, докато системи за съхранение като ZFS добавят допълнителен слой на надеждност чрез дедупликация и компресия.
Интеграция с бизнес процеси
MD Zero настройва клъстерите да се интегрират безпроблемно с вашите съществуващи системи, като ERP (напр. SAP, Oracle NetSuite), CRM (напр. Salesforce) или други бизнес приложения. Това се постига чрез API интеграции, middleware решения като Apache Kafka за обработка на потоци от данни в реално време или чрез директна връзка към бази данни с поддръжка на клъстериране (напр. MongoDB Sharding, Cassandra). Процесът на интеграция включва тестване за съвместимост, настройка на мрежови политики и оптимизация на производителността, за да се гарантира, че преходът е плавен и без загуба на данни.
Как се управлява услугата?

Централизирано управление
Ние предоставяме инструменти за управление на клъстерите, които позволяват на ИТ екипа да следи и контролира системата от единен интерфейс. Например, с Prometheus се събират метрики, като използване на CPU, RAM и мрежова пропускателна способност, докато Grafana визуализира тези данни в реално време чрез персонализирани табла (dashboards). Това улеснява бързото откриване на проблеми, като претоварени възли или мрежови задръствания, и позволява незабавна реакция.
Автоматизирани процеси
За да се намали ръчната намеса, внедряваме автоматизация чрез инструменти като Ansible за управление на конфигурацията, Jenkins за CI/CD тръбопроводи и Cron задачи за редовни актуализации. Например, ако е необходима актуализация на операционната система, Ansible може да я приложи към всички възли едновременно, като минимизира времето за престой чрез rolling updates (постепенно обновяване).
Персонализирани решения
Всеки бизнес има уникални изисквания, затова MD Zero разработва индивидуални стратегии за управление. Това може да включва настройка на специфични политики за балансиране на натоварването, конфигуриране на автоматични бекъпи с инструменти като Rsync или Bacula, или дори внедряване на системи за управление на инциденти (incident management) като PagerDuty.
Как се предоставя поддръжка?

24/7 техническа поддръжка
MD Zero осигурява денонощна поддръжка чрез сертифициран екип, който е на разположение да реши проблеми, като мрежови сривове, софтуерни грешки или хардуерни повреди. Поддръжката се осъществява чрез тикет система, телефонна линия и отдалечен достъп, като времето за реакция обикновено е под 15 минути за критични инциденти.
Проактивен подход
Освен реактивна помощ, ние предлагаме проактивна поддръжка, чрез системи за предсказуем анализ. Например, с помощта на машинно обучение и инструменти като Nagios или Zabbix, системата може да предвиди потенциални проблеми – като изчерпване на дисково пространство или необичайна мрежова активност – и да предприеме действия преди те да повлияят на бизнеса. Това включва автоматично увеличаване на ресурсите или изпращане на предупреждения до администраторите.
Процедури при инциденти
При срив на възел, следва стриктен процес: първо се анализират логовете (напр. чрез ELK Stack – Elasticsearch, Logstash, Kibana), след това се идентифицира причината (хардуерна повреда, софтуерен бъг или мрежов проблем), и накрая се прилага решение – от рестартиране на услугата до замяна на дефектен компонент.
Какви технологии се използват?

Модерни софтуерни решения
MD Zero разчита на водещи технологии за управление и автоматизация на клъстерите. Kubernetes се използва за оркестрация на контейнери, като поддържа функции като автоматично мащабиране (Horizontal Pod Autoscaler), самовъзстановяване (self-healing) и управление на мрежови политики. Docker или Podman осигуряват контейнеризация, докато Ansible и Terraform автоматизират внедряването и конфигурацията на инфраструктурата. За обработка на големи данни се използват платформи като Apache Hadoop, Spark или Flink.
Хардуер от последно поколение
За да постигнем максимална производителност, ние използваме сървъри с процесори Intel Xeon Scalable (3-то или 4-то поколение) или AMD EPYC (с до 64 ядра на процесор), бърза ECC памет (DDR5 с честота до 4800 MHz) и NVMe SSD дискове с капацитет до 15TB и скорост на четене/запис над 7000 MB/s. Мрежовите карти поддържат 25GbE или 100GbE, а за HPC задачи се добавят GPU модули като NVIDIA A100 или AMD Instinct MI250.
Мрежови технологии
Клъстерите са свързани чрез технологии като Software-Defined Networking (SDN) с платформи като Cisco ACI или OpenFlow, което позволява динамично управление на трафика. За приложения с високи изисквания към латентността се използва InfiniBand (с пропускателна способност до 200 Gbps), докато за стандартни конфигурации Ethernet с Jumbo Frames е достатъчен.
Допълнителни инструменти
За сигурност се използват системи като HashiCorp Vault за управление на тайни (secrets), OpenVPN за защитени връзки между възлите и SELinux за контрол на достъпа на ниво ядро.
Какви ресурси са необходими?
Човешки ресурси
За успешното внедряване и управление на клъстери, MD Zero препоръчва екип от системни администратори, DevOps инженери и специалисти по мрежи. Минималните изисквания включват познания по Linux (команди като top, df, netstat), опит с контейнери (Docker, Kubernetes) и основни умения в мрежовите протоколи (TCP/IP, DNS, DHCP).
Технически ресурси
Необходим е хардуер, включващ сървъри (поне 2-3 за базов клъстер), мрежови комутатори (напр. Cisco Nexus или Arista) с поддръжка на 10GbE или по-висока скорост, и рутери с висока пропускателна способност. Софтуерът включва операционна система (препоръчително Ubuntu 20.04 LTS или RHEL 8), инструменти за управление (Kubernetes, Ansible) и системи за мониторинг (Prometheus, Grafana). За съхранение са нужни бързи дискове – NVMe за производителност или SAS/SATA за по-голям капацитет – конфигурирани в RAID 5/6/10 за резервираност.
Енергийни и пространствени изисквания
Клъстерите изискват стабилно захранване (поне 2 независими линии с UPS системи) и ефективно охлаждане, особено при HPC конфигурации с висока плътност на изчислителна мощ. Пространството зависи от броя на сървърите – за малък клъстер са достатъчни 2-3 rack units (RU), докато големите HPC системи могат да заемат цял шкаф (42 RU).
Финансови ресурси
Инвестицията в клъстери варира значително в зависимост от мащаба и сложността на решението, което избирате.
Какви видове клъстери съществуват?
Отказоустойчиви клъстери (HA)
Тези клъстери са проектирани да осигурят непрекъсната работа при срив на компоненти. Настройват се с технологии като Pacemaker и Corosync за управление на отказоустойчивостта, като се използва активен-пасивен (active-passive) или активен-активен (active-active) режим. Например, в активен-активен HA клъстер всички възли обработват заявки едновременно, докато при срив един от тях поема цялото натоварване. Това е идеално за банки, болници или телекомуникационни компании.
Високопроизводителни клъстери (HPC)
HPC клъстерите са оптимизирани за задачи с висока изчислителна интензивност, като симулации на климата, геномни анализи или машинно обучение. Изграждат се с GPU модули (напр. NVIDIA Tesla V100 или A100), високоскоростни мрежи (InfiniBand с 200 Gbps) и софтуер като MPI или OpenMP за паралелна обработка. Те са подходящи за университети, изследователски центрове и технологични компании.
Уеб клъстери
Този тип клъстери е предназначен за уеб приложения и онлайн услуги, като разпределя трафика чрез балансьори като Nginx или Apache Traffic Server. Настройват се с кеширащи системи (напр. Redis, Memcached) и CDN интеграция, за да осигури бързо зареждане на страници и висока достъпност. Те са идеални за електронна търговия, медийни платформи и социални мрежи.
Хибридни клъстери
MD Zero предлага и хибридни клъстери, които комбинират локални и облачни ресурси. Например, част от задачите могат да се изпълняват на локални сървъри, докато пиковото натоварване се прехвърля към AWS EC2 инстанции чрез Kubernetes Federation.
Различие между всички видове решения
Специфични приложения
HA клъстерите се фокусират върху надеждност и минимален престой, използвайки технологии за репликация и failover. HPC клъстерите наблягат на изчислителна мощ и паралелна обработка, докато уеб клъстерите са оптимизирани за достъпност и бърз отговор на HTTP заявки. Хибридните решения комбинират предимствата на всички типове, като предлагат гъвкавост за сложни сценарии. MD Zero анализира нуждите ви, за да избере най-подходящия вариант.
Сложност и цена
HPC клъстерите са най-сложни и скъпи заради специализирания хардуер (GPU, InfiniBand) и софтуер (напр. SLURM за управление на задачи). HA и уеб клъстерите са по-прости и достъпни, като изискват стандартен хардуер и по-малко ресурси за поддръжка. Хибридните решения са средно ниво по сложност, но цената зависи от използваните облачни услуги. Ние предлагаме ценови модели, които балансират първоначалната инвестиция и дългосрочните разходи.
Технически изисквания
HPC изисква мрежи с ултраниска латентност (InfiniBand или RoCE), докато HA и уеб клъстерите работят добре с Ethernet (1GbE или 10GbE). HA системите изискват синхронизация на данни (напр. DRBD за блокова репликация), докато уеб клъстерите разчитат на кеширане и сесийно управление (напр. Redis за съхранение на сесии). Хибридните клъстери добавят сложност с мрежови тунели (VPN, VPC peering) между локални и облачни ресурси.
Примери за употреба
HA е подходящ за база данни с критични транзакции (напр. Oracle RAC), HPC за рендиране на 3D анимации, уеб клъстер за платформи като WordPress с милиони посещения, а хибриден за компании с променливи нужди (напр. сезонни кампании).
Как да изберете правилното решение?

Анализ на нуждите
MD Zero извършва задълбочен технически одит, за да определи най-подходящия тип клъстери. Това включва анализ на текущото натоварване (CPU, RAM, I/O), вид на приложенията (уеб, база данни, изчисления) и изисквания за наличност. Например, ако управлявате уебсайт с висок трафик, уеб клъстер е най-добрият избор, докато за научни изследвания HPC е задължителен.
Бюджет и цели
В зависимост от финансовия Ви капацитет и дългосрочните цели, MD Zero препоръчва решения, които балансират цена и производителност. За малки фирми с ограничен бюджет HA клъстер с 2-3 възела е достатъчен, докато големите фирми могат да инвестират в HPC или хибридни системи за по-сложни задачи.
Технически критерии
Изборът зависи и от технически фактори: брой потребители, обем на данните, латентност на мрежата и съвместимост с текущия софтуер.
Какви мерки за сигурност се предприемат?

Защита на данните
MD Zero внедрява многослойна сигурност чрез TLS/SSL криптиране за комуникация между възлите, защитни стени (напр. iptables, pfSense) за филтриране на трафика и системи за откриване на прониквания (IDS) като Snort или Suricata. Данните на диска се защитават с AES-256 криптиране, а ключовете се управляват чрез HashiCorp Vault.
Редовни актуализации
Софтуерът и фърмуерът на клъстерите се обновяват редовно, за да се справят с уязвимости, регистрирани в бази като CVE (Common Vulnerabilities and Exposures). MD Zero използва автоматизирани системи като yum-cron или apt-get за прилагане на кръпки, като тестване се извършва в staging среда преди внедряване в продукция.
Резервно копиране и възстановяване
MD Zero настройва автоматични бекъпи чрез инструменти като Rsync, Bacula или Veeam, с репликация на данни в географски различни локации (напр. чрез AWS S3 или Azure Blob Storage). При срив системата може да се възстанови за минути чрез предварително подготвени снапшоти (snapshots) или инкрементални копия.
Мониторинг на заплахи
За откриване на атаки в реално време се използват SIEM системи (напр. Splunk, Graylog), които анализират логове за подозрителна активност – като многократни неуспешни опити за вход или необичайни мрежови модели.
Как да оптимизирате ресурсите си?
Ефективно разпределение
MD Zero използва алгоритми за балансиране на натоварването, като Kubernetes Scheduler или HAProxy, за да предотврати претоварване на отделни възли. Ресурсите се ограничават чрез cgroups (напр. лимит от 4 CPU ядра и 16GB RAM на контейнер), което гарантира равномерно разпределение.
Мониторинг и анализ
С инструменти като Zabbix, Prometheus и ELK Stack, MD Zero ви позволява да следите използването на ресурсите в реално време. Например, ако един възел използва 90% от диска си, системата изпраща предупреждение и може автоматично да прехвърли данни към друг възел с повече свободно пространство.
Виртуализация и контейнеризация
Чрез технологии като KVM, VMware или Docker, се увеличава ефективността на хардуера, като позволява на множество виртуални машини или контейнери да работят на един физически сървър. Това намалява празния ход (idle time) и оптимизира консумацията на енергия.
Оптимизация на мрежата
MD Zero настройва мрежови политики с QoS и трафик шейпинг, за да приоритизира критичните приложения (напр. база данни пред файлови трансфери), като използва инструменти като tc (Traffic Control) или Cisco QoS.
Как да надградите услугата?
Добавяне на нови възли
MD Zero улеснява надграждането чрез добавяне на нови сървъри към клъстерите, като използва автоматично откриване на възли (node discovery) в Kubernetes или ръчна регистрация в HA системи. Процесът включва инсталиране на предварително конфигуриран образ (image) и синхронизация на данни чрез rsync или Ceph.
Технологични подобрения
С внедряване на нови процесори (напр. Intel Sapphire Rapids с поддръжка на PCIe 5.0) или по-бързи мрежи (100GbE или 400GbE), MD Zero поддържа системата ви актуална. За HPC задачи могат да се добавят нови GPU модули, като NVIDIA H100, които предлагат до 3 пъти по-висока производителност спрямо предишни поколения.
Миграция към облака
MD Zero може да прехвърли вашите клъстери към хибридни или изцяло облачни решения, като използва платформи като AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS) или Google Kubernetes Engine (GKE). Това включва настройка на VPC peering или VPN тунели за сигурна връзка между локални и облачни ресурси.
Планиране на надграждането
Процесът започва с анализ на текущата производителност, идентифициране на тесни места (напр. бавен I/O или недостатъчна памет) и изготвяне на план за разширяване, който минимизира прекъсванията чрез rolling updates.
Автоматизация и ефективност
Намаляване на ръчната работа
MD Zero използва автоматизация чрез Ansible, Terraform и Bash скриптове, за да минимизира ръчните конфигурации. Например, внедряването на нов възел може да се извърши с еднократна команда, която инсталира софтуера, настройва мрежата и го добавя към клъстера.
Повишаване на производителността
С автоматично мащабиране (autoscaling) в Kubernetes, клъстерите адаптират ресурсите към текущото натоварване – например, увеличаване на броя на контейнерите при пиков трафик и намаляването им при спад. Това подобрява ефективността и намалява разходите за неизползвани ресурси.
Интеграция с CI/CD
Настройват се тръбопроводи за непрекъсната интеграция и доставка (CI/CD) с инструменти като Jenkins, GitLab CI или GitHub Actions. Това позволява на разработчиците да публикуват нови версии на приложенията директно в клъстера, като се използва blue-green deployment или canary release за минимален риск.
Примери за автоматизация
Автоматизирано архивиране на база данни се настройва с Cron и mysqldump, докато мониторингът на системата изпраща известия чрез Slack или email при превишаване на прагове (напр. 80% CPU за повече от 5 минути).
Често задавани въпроси